Данная заметка является адаптацией и расширением статьи "The fallacies of distributed systems".
Более 20 лет назад Питер Дойч и другие сотрудники Sun Microsystems составили список ложных предположений, которые делают многие разработчики, начинающие работу с распределенными приложениями.
Эти предположения всегда оказываются неверными, что затрудняет исправление ошибок. Здесь мы рассмотрим эти восемь заблуждений более подробно.
Учитывая, что после покупки Oracle-ом Sun Microsystems, о последней особо не вспоминают, да и произошло это довольно давно, напомню:
Sun Microsystems — американская компания, производитель программного и аппаратного обеспечения, основанная в 1982 году. Среди разработок:
- База данных MySQL
- Язык и платформа Java
- Пакет офисного ПО OpenOffice
- Процессорная архитектура SPARC
- Операционная система Solaris
- Файловые системы NFS и ZFS
И многое другое. Я перечислил то, о чём вы, вероятно, слышали.
Заблуждение №1: Сеть надежна
При создании распределенной системы опасно полагать, что сеть, соединяющая компоненты, работает идеально.
На самом деле сети по своей сути ненадежны: пакеты могут быть потеряны, соединения могут быть прерваны, а данные могут быть повреждены во время передачи. И это только начало.
Чтобы построить надежную систему, нам нужно принять и запланировать эти потенциальные сбои. Эффективной стратегией является создание механизмов ретрансляции. Шаблон "сохрани и перешли" - один из распространенных способов сделать это.
Сохрани и перешли (Store and forward) - это сетевая техника, при которой информация отправляется на промежуточную ноду, где она сохраняется и позже отправляется в конечный пункт назначения или на другую промежуточную ноду.
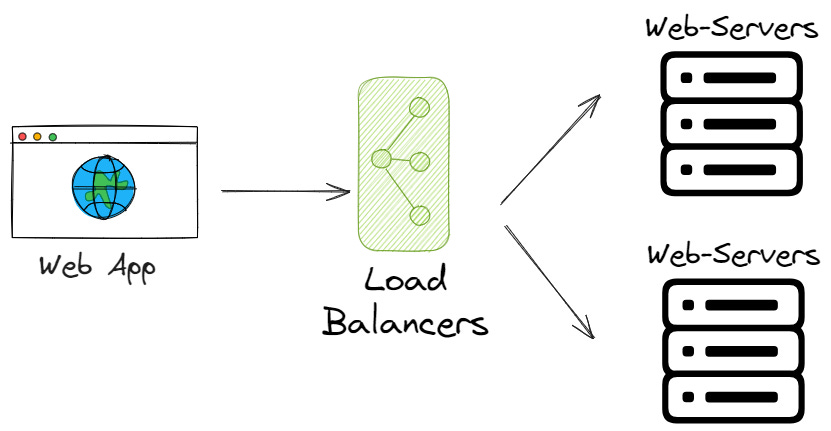
Вместо того чтобы напрямую отправлять данные на нижестоящий сервер, мы можем хранить их локально или в промежуточном месте. Это позволяет выполнять повторные запросы и дает возможность вернуться к исходному состоянию в катастрофических ситуациях, когда простой цикл ретраев не сработает.
Правильная политика ретраев, информирование о нагрузке, ключи идемпотентности (в особенности) и многое другое... Обо всём этом нужно помнить, когда мы говорить об отказах сети / нижестоящих серверов.
Брокеры сообщений, такие как RabbitMQ и ActiveMQ, идеально подходят для поддержки этого паттерна, как и различные облачные решения, предлагаемые крупными поставщиками.
Заблуждение №2: Задержка равна нулю
Задержка / латентность - это время, необходимое для перемещения данных из одного места в другое. Это факт, который нельзя игнорировать в распределенных системах.
Часто можно встретить, что задержкой или "латенси" называют время, которое проходит от посылки запроса до получения ответа.
Этим грешат многие и на столько часто, что как будто все смирились. Это как путать понятия "цифра" и "число".
Есть латенси и время отклика (response time).
Время отклика - это время, за которое система обрабатывает запрос и возвращает результат. Например, в веб-приложении время отклика - это промежуток времени между нажатием на ссылку и полной загрузкой страницы.
Латенси - это лишь часть времени отклика. Та часть, которую запрос летит по сети, находится в различных буферах и т.д.
Латентность - это как дополнительная работа, которую приходится выполнять каждому запросу. Независимо от того, большие или маленькие сообщения, задержка остается постоянной, поскольку на нее в первую очередь влияют скорость света и расстояние между взаимодействующими системами.
Самый очевидный способ уменьшить задержку - переместить данные ближе к клиентам. В облачной среде мы можем тщательно выбирать зоны доступности в зависимости от местоположения клиентов.
Кроме того, мы можем использовать кэширование для уменьшения количества сетевых обращений и дублировать данные ближе к месту, где они нужны, с помощью сетей доставки контента (CDN).
Заблуждение №3: Пропускная способность бесконечна
Пропускная способность - это объем данных, который может быть передан за определенное время, и она не безгранична. С течением времени пропускная способность улучшилась, но вместе с ней увеличился и объем передаваемых нами данных.
Современные приложения, такие как VoIP или потоковое видео, потребляют много пропускной способности. Даже такие простые вещи, как пользовательские интерфейсы и многословные форматы данных (например, XML и JSON), увеличивают объём передаваемых данных.
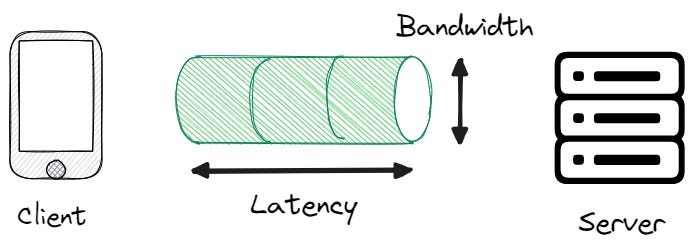
Существует тонкий баланс между минимизацией задержек и экономией пропускной способности. Мы должны передавать больше данных за меньшее количество циклов, чтобы уменьшить задержку. Однако для экономии полосы пропускания нам нужно передавать меньше данных в целом.
Эффективные форматы данных и сжатие - все это помогает справиться с ограничениями пропускной способности.
Также нужно оценить, что для нашего сервиса важно и на сколько: низкое время отклика, или же высокая пропускная способность. Они находятся в некотором конфликте.
К примеру, часто проще (дешевле по CPU и т.д.) обработать запросы сразу целой пачкой, нежели по одному. То есть, начинаем буферизировать запросы. Так мы поднимаем пропускную способность, но и латенси (и время отклика) растёт.
Заблуждение №4: Сеть безопасна
Предполагать, что сеть, которую мы используем, безопасна, - критическая ошибка. Безопасность должна быть главным приоритетом с ростом программ «bug bounty» и частыми новостями о крупных эксплойтах.
Зловреды постоянно пытаются перехватить и расшифровать сетевые сообщения. Это делает шифрование данных и снижение рисков безопасности крайне важными.
Забота о безопасности с самого начала проектирования системы всегда оправдывает себя в долгосрочной перспективе. Кроме того, важно найти время, чтобы внимательно изучить возможные угрозы безопасности.
В распределённой системе стоит использовать mTLS, где не только сервер, но и клиент должны подтвердить свою подлинность.
Также стоит не забывать о разграничении прав доступа пользователей к ресурсам. Ну и в логах иметь информацию о том, действие какого пользователя нас привели в данную точку.
Заблуждение №5: Топология не меняется
Структура сети не является статичной. Она часто меняется, иногда из-за того, что что-то ломается, но чаще всего потому, что мы специально добавляем или удаляем компоненты.
С развитием облачных вычислений и контейнеризации изменения топологии сети становятся еще более частыми. Кроме того, эластичное масштабирование, когда мы добавляем или удаляем серверы в зависимости от рабочей нагрузки, требует гибкости.
Zookeeper и Consul - отличные инструменты, которые помогают решить проблемы с обнаружением сервисов и позволяют приложениям адаптироваться к изменениям в том, как устроены наши системы и как они работают.
Изменение топологии также может повлиять на латенси. Есть большая разница: идёт ли запрос от микросервиса к микросервису в рамках одной серверной стойки, или же они находятся в разных зданиях.
Заблуждение №6: Существует один администратор
Когда система растет, она часто зависит от внешних систем, которые мы не контролируем. Это означает, что мы не можем управлять всем сами.
Очень важно учитывать все зависимости: от нашего кода до серверов, на которых мы работаем. По мере увеличения количества систем и конфигураций становится сложно управлять и отслеживать все.
Первый способ - внедрить надежные инструменты мониторинга и наблюдения, которые очень важны для быстрой диагностики проблем при их возникновении.
Для проверки, так ли хорош ваш мониторинг, советую воспользоваться Проверочным списком. Там же вы сможете найти идеи, как улучшить ваш мониторинг.
Кроме того, использование инфраструктуры как кода (IaC) для кодирования вариаций системы и уделения особого внимания соответствующему развязыванию помогает обеспечить общую устойчивость и работоспособность системы.
Заблуждение №7: Транспортные расходы равны нулю
Передача данных между системами - это простая бизнес-оценка только в том случае, если система небольшая. Однако по мере роста систем затраты на транспортировку данных становятся все более значительными.
В определенный момент мы можем подумать, что это стоит оптимизировать. Например, такие форматы сообщений, как JSON, могут быть тяжелее, чем оптимизированные для передачи данных форматы, такие как gRPC.
В облачных средах, таких как AWS, затраты на передачу данных между регионами или зонами доступности реальны и могут быстро увеличиваться.
Знать об этих расходах очень важно. Однако это имеет свои недостатки. Если мы оптимизируем слишком рано, это может принести нам больше проблем, чем пользы в краткосрочной перспективе.
Заблуждение №8: Сеть однородна
Хотя нам нравится, когда все чисто и аккуратно, реальный мир далек от этого. Например, нам часто приходится преобразовывать один формат данных в другой.
При этом важно обеспечить совместимость. Благодаря этому наши системы будут работать, даже если выйдет новый фреймворк или нам придется использовать их в местах, для которых они не предназначены.
Однако совместимость имеет свои пределы. Нам нужно найти правильный баланс. Мы можем сэкономить время и избежать проблем в долгосрочной перспективе, если будем помнить, что не все системы одинаковы, и избегать привязки нашего решения к одному конкретному аспекту.